Technology
What is end-to-end encryption and why are tech companies focusing on it?


Life is an endless process of taking multiple decisions be it professional or personal. “What do I need to keep in mind before I present my talk to this diverse audience?”, “I need to hire the right person for this job without being unconsciously biased”, or even “What should I order for lunch today? Too many places to order from!” and many more.
This article will explain to you a tool which can help influence your decision in a positive way. With this tool, we will be entering into the complex world of Data Science albeit without all the complexity as amazing data scientists have made it a bit easier for us. You just need to know how to put these techniques in innovative solutions. In this article, we will combine two simple yet powerful tools to get started.
Data is everywhere. It is not just in the form of numbers or text but also images, videos, and audio files. To use data efficiently, we need to classify the data properly and put it into the right categories. Classified data is used to take better decisions in different fields such as marketing, advertising, finance, healthcare, education and many more. To give you an example, a departmental store might decide which two products should be given as a combo offer to attract more customers. A bank may decide in minutes whether this customer can get a loan or not by analysing their credit history by running various classified data through some algorithms.
You must have heard phrases like, “this person is speaking from his/her experience”, or “speaking from my experience, I think you should take route B to reach faster”. What is this ‘experience’ if not a collection of classified data that a person collects over the years?
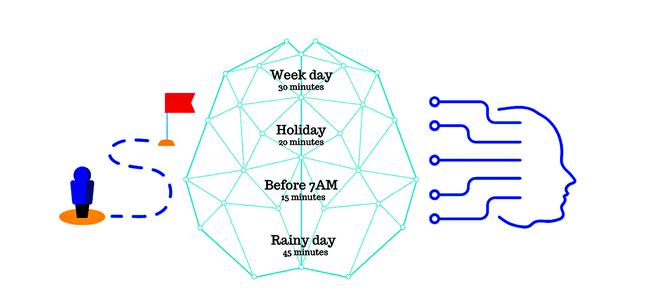
For example, let’s say you are going to your office or school — somewhere you have to commute regularly. It’s Monday and you started from home at 9 AM and reached at 9:30 AM. Your mind stored and tagged this data as taking 30 minutes to reach your destination. After two days, on a Wednesday, you reached at 9:20 AM because you realised that it is a bank holiday. Now you can reach the destination on a holiday in 20 minutes. And slowly as you continue to encounter different traits that affect your travel time, you keep on classifying and storing this data in your mind for future reference. After a year or so, you gain that ‘experience’ to direct someone else with the classified data in your head to make better decisions.
But as the data gets larger and decisions get more complex, we would need mechanisms to continually tag and maintain such data. For that we need tools. But before we jump into learning how to use these tools, let us take a quick look at the technical terms.
Zero Shot Text Classification is a new and innovative machine learning technology that enables computers to classify texts without any prior knowledge of the statements. This technology has been developed by a team of researchers from the University of Copenhagen. It helps in labelling your text data without training any data model. But what is a trained data model?
Think of a trained model as a brain, which is programmed to be filled with ‘experiences’ to help you make decisions. This is also one of the reasons why it’s called zero shot learning because we don’t have to provide any set of labelled data during the training of the classifier. We try to use a trained classifier to label a text that we want to classify.
To better understand zero shot learning, imagine a young girl who has seen pictures of different horses and thinks that she knows the animal pretty well. Suddenly one day the girl sees a zebra, the first classification that will come to her mind is that “this is a horse!”. But then this can be correctly classified by an adult whose mind has a better classification of similar looking animals. The adult can then help the girl learn that this is not a horse but a zebra. This instance not only helps the girl correctly identify the animal, but also creates a new classification in her mind. This cycle may continue with the adult seeing an okapi for the first time. Okapis are also known as a zebra giraffes, found mostly in Central Africa. The same adult might now classify this animal as “some kind of horse or zebra”, until someone else who has seen this animal before helps the person learn that this is an okapi.

With this basic knowledge, let us try to use this technique of classification with Google Sheets and the Hugging Face library.
Google Sheets is a spreadsheet application from Google that lets you create and edit spreadsheets on the web, from either a browser or the Google Sheets app. If you have an email setup with Gmail, you already have access to Google Sheets. If not, please create a free email id with Gmail.
Hugging Face is a community and data science platform that provides tools that enable users to build, train and deploy machine learning models based on open source (OS) code and technologies. There are many trained models available with hugging face libraries, that are very powerful and can be combined with programming languages like Python to create amazing data science applications. But for this exercise, we will not be using any programming, just a small code that the Hugging face team created to be used behind Google Sheets, which will actually provide your sheet with a mechanical brain to classify text data. Let’s get started.
Step 1: Navigate to https://huggingface.co/
Step 2: Click on signup and provide the necessary information to create your account.

Step 3: Retrieve your token.
Once logged in, click on the Inference API Dashboard available under the user profile in the top right corner.

Now click on tokens under profile.

On the next page, click on ‘New token’ and give it a name. After the token is generated, copy and paste it on a note or document.

Assuming that you already have a Gmail account or have created one, let’s now set up your Google sheets.
Step 1: Navigate to https://sheets.google.com and open a blank sheet and give it a name, say “Zero shot classification”
Step 2: Click on “extensions” and then click on “App Script”. This will open the App script editor.

Step 3: On the App script editor, paste the below code. This code was created by the Hugging Face team. It can also be directly copied from their github gist page below.
https://gist.github.com/feconroses/302474ddd3f3c466dc069ecf16bb09d7
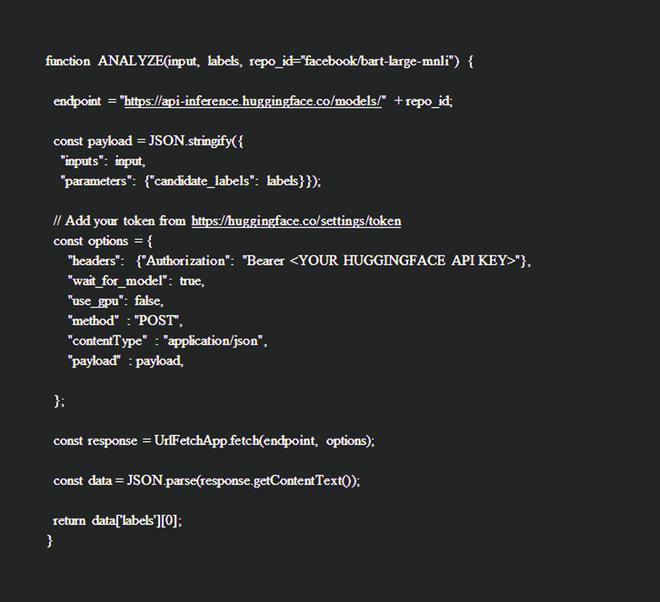
In the code, replace the <YOUR HUGGINGFACE API KEY>, with the Token that you saved in the previous step.
That’s it! You are now ready for the magic. Let’s test and see whether it works.
Suppose we have to categorise a few statements under three broad topics — Chess, Technology and Politics. For that one has to create the column names first after which you can name them in any way that is meaningful to you. Here we have named the three columns as Text, Classification and Labels.

Now under Text, write some random statements and under Labels, write Chess, Technology, and Politics.

Now under Classification, write the below formula using the analyze() function you created in the App script editor.
=analyze(A2, E$2)
Don’t forget the ‘=’ before the formula. This will help Sheets to evaluate and put the result in the Classification cell. The first parameter A2 means it’s picking up the first statement “ I always play the Caro Kann opening as black”. The E$2 parameter helps to identify the Labels.

The moment you press enter, you will see that it has identified the statement as Chess (as Caro Kann is an opening for moving black in chess). Now just copy the formula for the other two statements as well. You need to change the first parameter from A2 to A3 and A4 so that it picks up the second and third statement respectively. You will see that the next two statements, “ I need to get an Arduino to start home automation” and “ Demonetisation was a great step towards a better future by our Prime Minister” are classified automatically as Technology and Politics.

We have now seen how a complex classification system can be implemented very easily. While you can now use or extend this for many other classifications, let’s try one more simple but powerful use case — an unbiased sentiment analysis.
For example, let's say you are going to facilitate a workshop for a group of participants on some subject. It is always better to start by asking a simple question to the group about how they were feeling about the subject or the workshop in general. This helps us to better modulate the talk so as to cater to different sentiments. For example, if everyone says that the topic is difficult and that they are afraid or unsure, one knows that the workshop needs to be executed in a more engaging manner with lots of analogies. But usually what happens is that people start giving positive remarks so as to not seem vulnerable within a group. So, we would probably end up getting some false positives. Can we make this process a bit more productive?
Let’s say, instead of asking how they are feeling about the topic, we ask them to give any random number of statements that are coming to their heads now, which is not related to the workshop at all. Suppose they come up with the statements below:
My house help did not come today
I don't know how to use my new phone
What a great morning this is
Life is beautiful
I wish I could go home
I want to be rich
I think I can change the world
I have so much work left
Now if we put these texts in the same Google sheet and have some labels like Happy, Sad, Hopeful, Excited, Angry, Confused, Irritated, we can understand how they are feeling at the moment. This process will be a lot more unbiased and may also reduce the chances of false representation.
Check the below result for the same.

This is a relatively small example. There could be much bigger cases such as segregating knowledge assets in organisations, universities or schools. This is one of the challenges that industries are facing currently — classifying valuable knowledge assets, specially in the remote age. Have a look at this article from Asyncagile to understand why it is important for an organization to classify the huge and untraceable knowledge for a sustainable strategy.
I am really interested to know how you will be using this in your day-to-day decision making. Let me know by email or social channels, whichever is convenient to you.
Also, if you are interested, using this google form, let me know how you feel after reading this article. I will collect all the statements and perform a sentiment analysis on them and then share it with you through social channels. Quite an experiment, isn’t it? All the best and keep innovating.
Jaydeep is the Head of Communities at Thoughtworks, India. He can be reached at jaydeepc@thoughtworks.com via email and @jchakrabarty on twitter and LinkedIn.