Technology
What is end-to-end encryption and why are tech companies focusing on it?


A picture speaks a thousand words. Perhaps this is the reason why the number of pictures stored on our devices have grown dramatically. Don’t we all recognise the inclination to use an emoji instead of an over-long text response making services such as SnapChat, Instagram and TikTok to become some of the most popular internet platforms.
Organising these images on our devices can be tedious which is why cloud-based storage platforms by Google and Apple offer automatic sorting of images. These are driven by advancements in computer vision algorithms, particularly, developments in Machine Learning (ML) methods. In this tutorial, we will attempt to build a simple image classifier and run it on a local computer which has Python installed on it. Just to make it more interesting we will try to tell jalebis from samosas!
The starting point of all ML model development is to get well-curated data. The data for the purposes of this tutorial can be downloaded from the link here. Once the data has been downloaded locally onto your computer, try and extract the archive in such a manner that the folder structure is retained. You should see the following contents inside the folder.
Browse the contents of the data folder, and you should see two more folders with the names of the food items we are trying to classify. Additionally, the folder also contains the Python code in the form of an interactive Python notebook (ipynb), which the reader can tweak for later projects. Inside the data folder, there are some images of jalebis and samosas, which were crawled from the web released under the Creative Commons licence, which allow us to work with them.

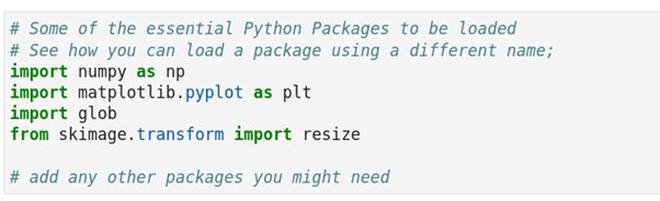
Now that the data has been downloaded, we will start using the Python programme for building the image classifier. The recommended environment for this project is the Jupyter-Lab Python environment, but more advanced users can use any other integrated development environment. Once inside your favourite Python programming environment, load the initial libraries necessary for reading and visualising the images. Browse the folder where the contents from the downloaded archive are present.
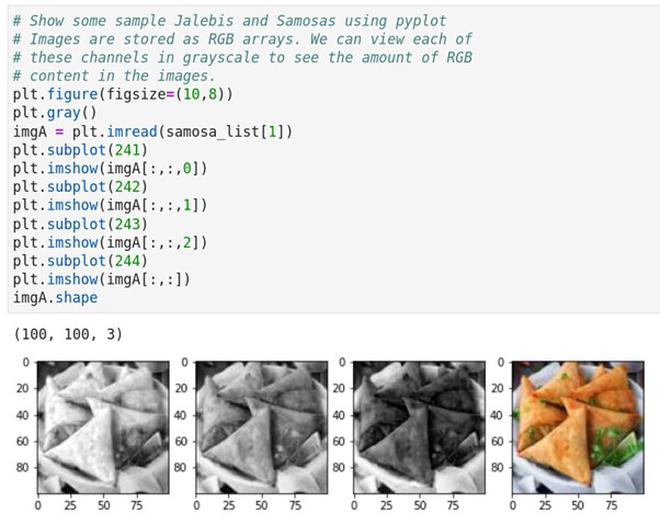
It must be noted that JPG images are stored as numerical arrays and that each number represents the intensity of that pixel. Usually, 0 intensity corresponds to black and 255 corresponds to white and all numbers in between capture the 256 shades of grey. For colour images, there are three channels corresponding to the Red-Green-Blue (RGB) content in the images.
By using the image reading and viewing packages in the Matplotlib library, we can visualise the different channels of the images.
We will need to standardise these images, for which we will use the amount of RGB content in each of the images to describe them to the algorithms. So, the dataset we create will resize all these images to a fixed size and compute the average amount of RGB in each image. Thus, every image will be represented using only three features.
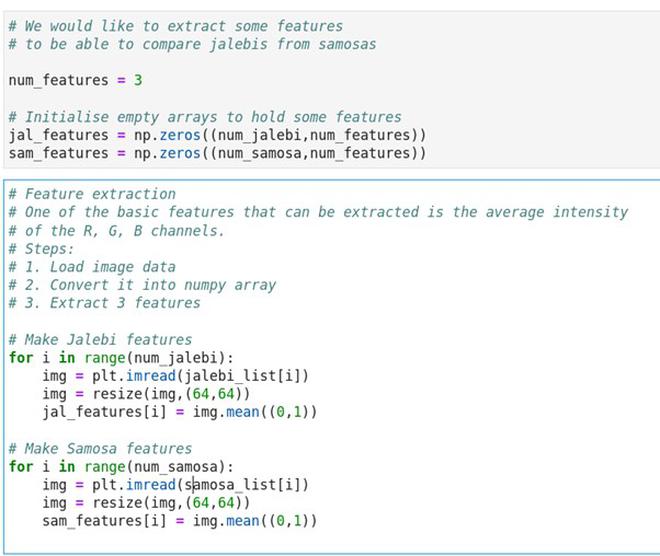
As computers cannot fully comprehend what jalebis and samosas are, we will use numbers to represent their labels. For instance, a jalebi can be 0 and a samosa can be 1.

The final step of making the dataset is to stack the two classes of data into a single array. This is a requirement for the ML framework we will be using in the next step.

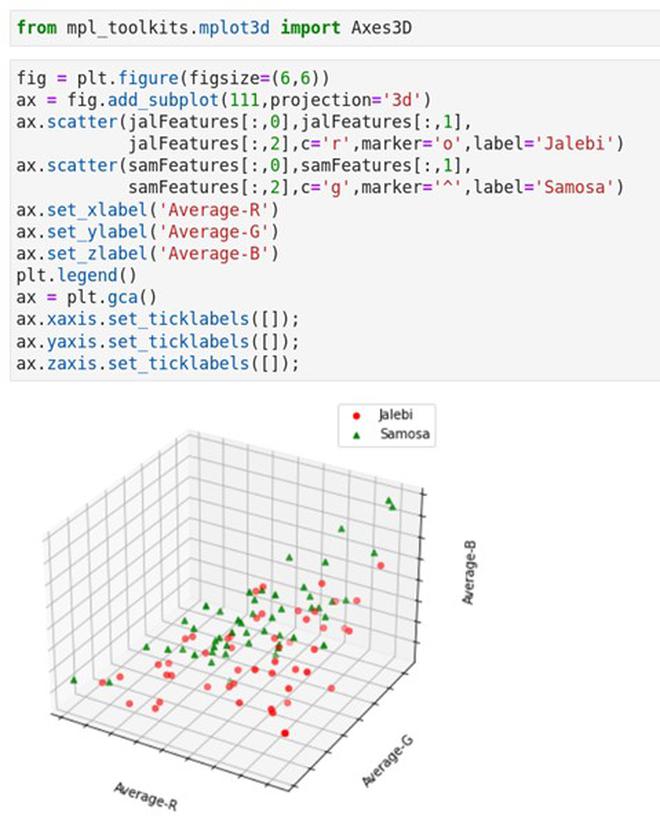
We can now visualise all the jalebis and samosas in the average RGB feature space. Each marker in this plot captures the amount of R, G and B content in these images. (see below)
Now that our dataset is ready, we can train a simple image classifier to automate the detection of jalebis and samosas. We will use the Scikit-Learn Python package, which has a comprehensive set of tools and algorithms that can be used for ML.
The first step of training an ML algorithm is to split the dataset for training and testing purposes. As the name suggests, the training set is used to train the ML algorithm and the test set is used to test the performance of it. The performance on the test set is more representative of how the algorithm will fare on new real-world data. We use 75% of the data for training and the remaining 25% for testing purposes.

The next step is to load the Python modules from Scikit-Learn which will be used to initialise our simple classifier. Here, we will use the simplest of the classifiers based on logistic regression. This classifier is constrained as a linear classifier and can be restrictive. However, these models can also be quite useful and for this tutorial we will confine to using such linear models. We will initialise the Logistic Regression classifier, train it on the training set and test it on the test set.
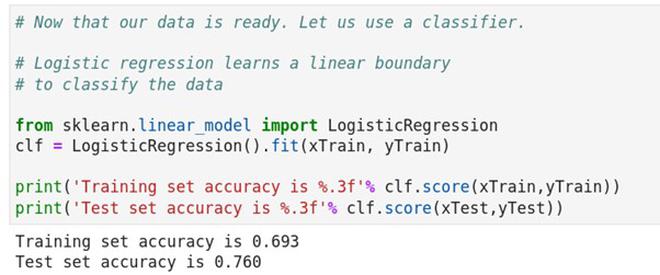
For this random training-test split, we obtain a training accuracy of about 70% and a test set accuracy of 77%. One must note that these numbers could vary quite a bit due to the randomness in the data shuffles and the initial model parameters.
Once you have trained a classifier, we can use the trained model to make predictions on new data. The Logistic Regression classifier predicts a score for how likely it believes a certain image belongs to a certain group. This can be treated as a probabilistic score.
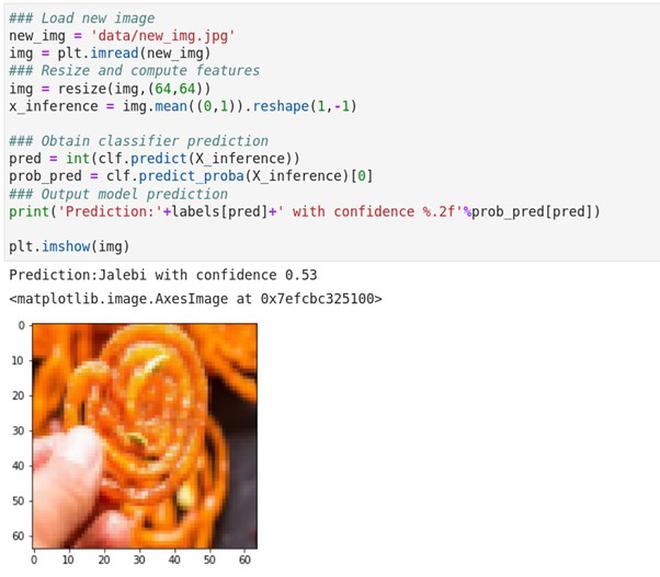
For now, we have explored the procedure to build a simple image classifier that can tell jalebis from samosas. Using this template, one can build more sophisticated algorithms. Simple extensions to this project could be to include additional food categories or to try out more complex algorithms. For the latter, Scikit-Learn has well documented algorithms with examples and could be a starting point.
Raghavendra Selvan is an Assistant Professor at the Department of Computer Science, University of Copenhagen